HTMLの基礎
Summary
この記事では、HTML の基礎やその歴史、HTML 文書の構造について学べます。
はじめに
この記事は、要素の役割や文字参照を含め、HTMLの目的や構造をまとめたものです。個別の機能は以降の記事で詳しく解説していきます。
HTML とは
ほとんどのソフトウェアは、専用のファイル形式を読み書きします。たとえば、Microsoft Word は “.doc” ファイルに対応し、Microsoft Excel は “.xls” に対応します。これらのファイルには文書内容のほかに、次に開いた時の再構築の手順を記す情報、「メタデータ」と呼ばれる文書に関する情報が格納されています。メタデータには、文書の執筆者や最終変更日、新旧のバージョンを行き来するための変更履歴などが含まれています。
HTML (“HyperText Markup Language”) は Web 文書の内容を記述する言語になります。HTML の構文では「要素 (elements)」と呼ばれる仕組みを利用します。要素は文書中のテキストを囲み、ユーザーエージェントにその箇所がどのような挙動をとればよいかを伝えるのです。
ここでは「Web ブラウザー」という言葉にかわり「ユーザーエージェント」という技術用語を使っています。ユーザーエージェントは、ユーザーのかわりに Web ページにアクセスするソフトウェア全般を指し示す言葉です。デスクトップブラウザー (Internet Explorer, Opera, Firefox, Safari など) やその他のデバイス用のブラウザー (Wii インターネットチャンネルや、Opera Mini, iPhone WebKit に代表されるモバイルブラウザー) は、もちろんユーザーエージェントになります。
しかし、ここで重要なのは、ブラウザーだけがユーザーエージェントではないということです。たとえば、Google や Yahoo! が自社の検索エンジンのために利用する、Web の自動インデックスプログラムもユーザーエージェントになります (ただし、この場合は人間が直接プログラムを操作することはありません)。
HTML はどんなもの?
HTML は文書の内容とその意味をプレーンテキストで表すフォーマットです。たとえば、以下のようなものです。
<p id="example">ここは段落です。</p>
この “<p>” という部分は段落を表すしるし (「開始タグ」と呼びます) になり、この場合は「このあとに続く部分を段落として扱う」という意味になります。そして、“</p>” は段落を終了するタグ (「終了タグ」と呼びます) になります。
「要素」とは、開始タグから、開始タグから終了タグの間にある内容と、終了タグまでを含めた箇所を指します。開始タグの中にある id="example" は属性といいます。これについては後ほど説明します。多くの人が要素の意味で「タグ」という言葉を使用しています (前述したとおり、これは厳密には正しくありません)。
多くのブラウザーには「ソース」または「ソースを表示」という機能が搭載されており、たいていの場合「表示」メニューから選択することができます。もし、あなたの利用するブラウザーがソース表示機能を提供していたら、選択してページの HTML ソースをしばらく眺めてみましょう。
HTML のあゆみ
インターネットと Web の歴史 では、どのように Web が成立したかその歴史が語られています。そしてそこには、Tim Berners-Lee が World Wide Web を発明したとき、彼は最初の Web サーバーと Web ブラウザー、そして HTML の最初のバージョン を作成したことが書かれています。
現在の HTML は、その初期のバージョンから大きく変化していますが、多くの内容は現在の HTML にも生きています。また、初期のバージョンに存在した「タグ」の半分以上は、今でも使われ続けています。
多くの人が Web ページを書き始め、最初のブラウザー以外にブラウザーが登場するようになってから、多くの機能が HTML に追加されていきました。そのうちの多くは広く使われるようになりました (文書に画像を挿入する img 要素がその例で、これは最初 NCSA Mosaic に実装されたものです)。いくつかの要素はプロプライエタリなもので、ひとつふたつ程度のブラウザーでしか採用されませんでした。
そのうち、HTML の標準化が求められるようになりました。HTML がどのように表示されるべきかを決定的にまとめた文書 (「仕様」と呼ばれます) があれば、Web ブラウザーを開発する人が HTML を実装するとき、適切に実装されているか確かめることができるからです。
この流れをうけ、IETF (Internet Engineering Task Force) というインターネットの相互運用性について検討する標準化団体が、HTML 仕様の素案を 1993 年に公開しました。この素案は標準にならず 1994 年に失効してしまいましたが、これが IETF に HTML の標準化を行う作業部会が組織されるきっかけになりました。
1995 年、最初の HTML の草案からアイデアをひろった “HTML 2.0” が策定されました。また、HTML+ という異なる提案も Dave Raggett によって執筆されました。HTML+ は、ブラウザーが実装した新しい要素 (NCSA Mosaic により始まった、画像を挿入する仕組みなど) の多くを基礎とする仕様でした。
同年の後半に、HTML 3.0 の草案が公開されました。しかし、このバージョンはその後の策定が打ち切られました。方向性に関してブラウザーベンダーの指示を取り付けられなかったためです。HTML 3.2 は HTML 3.0 の新機能の多くを廃し、その代わりとして当時人気だった Mosaic や Netscape Navigator というブラウザーが生み出した機能を取り入れることになりました。
1997 年、W3C は HTML 4.0 を勧告として公開しました。このバージョンでは、さらに多くのブラウザー固有の拡張が取り込まれていましたが、それらに理由をつけた上で HTML を整理する試みが行われていました。いくつかの要素を「非推奨」という、現仕様で定義されるが将来的に削除される事を明記したのです。こうすることで、より意味的な HTML の利用を推奨しようとしていました (詳しくは Web 標準のモデル をご覧ください)。
1999 年には改訂版である HTML 4.01 が公開されました (2001 年に正誤表が更新されています)。これが HTML の最終版になります。しかしながら、現在 HTML 5 の策定が進んでいる最中です。
2000 年に、W3C は XHTML 1.0 仕様を公開しました。これは、HTML を valid な XML 文書フォーマットになるよう再構成したものです。
HTML 文書の構造
シンプルで valid な HTML 文書は、次のようなものになるでしょう。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Example page</title>
</head>
<body>
<h1>Hello world</h1>
</body>
</html>
Web ブラウザーでは以下のように表示されます。
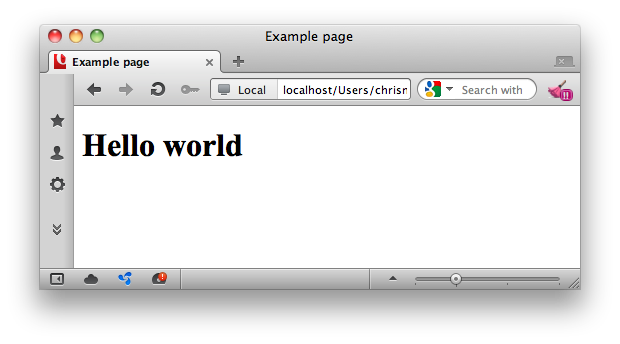
HTML 文書は、「文書型」もしくは「DOCTYPE 宣言」と呼ばれるものから始まります (詳しくは Choosing the right doctype for your HTML documents をお読みください) 。DOCTYPE 宣言は主に、"標準モード"と呼ばれるものでHTMLを正しくレンダリングするために役立ちます。またバリデーターは、どのHTMLのバージョンでコードを検証するかを知ることができます。現時点では、この意味が分からなくても心配ありません。おいおい解説していきます。この例では、HTML5のDOCTYPE宣言を見ることができます。
DOCTYPE 宣言の次にあるのが、html 要素の開始タグになります。これが、文書全体を囲む要素になります。ですから、html 要素の終了タグは、文書の最後に登場します。html要素は、常にlang属性を持つべきです。これは、ページの主言語を指定します。たとえば、en は"英語"を意味し、fr は"フランス語"を意味します。言語コードを見つけるために、Richard Ishidaの Language Subtag Lookup tool などのツールも使用できます。
html 要素の中には head 要素があります。これは、文書に関する情報 (メタデータ) を格納する部分になります。head 要素については 次の記事 でもっと詳しく解説します。head 要素の中にある title 要素が、ウインドウに表示されるタイトル (この場合は“サンプルページ”) を指定する要素です。head 要素には常に、ページの文字コードを識別する charset 属性を持つ meta 要素を含める必要があります。可能な限り UTF-8 を使用するべきでしょう。more about character encodings も参照してください。
head 要素のあとに body 要素が続きます。body 要素はページの内容を囲むもので、この例では “Hello world.” と書かれたひとつの第1レベル見出し ( h1 ) が文書の内容になります。
要素は他の要素を含むことが多いです。とくに文書の本文部分は、多くの入れ子になった要素から構成されることでしょう。article 、 header や div 要素などの文書構造要素は、いくつもの区画を構成し、各区画はさらに細分化された区画より構成されます。ここの区画は見出しや段落、リストなどを含むでしょう。段落は、他のページへのリンク、引用、強調などを含むことができます。これらの要素については、後ほど解説していきます。
HTML 要素の構文
基本的な HTML の要素は、テキストを2つのタグで囲ったものになります。そしてほとんどの要素は別の要素を囲むことができます(上記の例であれば、html が head と body を囲っています)。いくつかの要素では、テキストや他の要素を囲まないものもあります。たとえば img 要素です。これらについても、おいおい解説していきます。
要素は属性を持つことがあります。属性とは要素の挙動を変更したり、意味を付け加えたりするものです。別の例を見てみましょう。
<header>
<h1>The Basics of
<abbr title="Hypertext Markup Language">HTML</abbr>
</h1>
</header>
以下のように表示されます。

この例では、header 要素 (文書のヘッダーをあらわす要素) が h1 (最初、もしくは一番重要なレベルの見出し) 要素をもち、見出しとなるテキストが指定されています。テキストの中にはさらに、abbr 要素があり、その要素には title 属性が値 Hypertext Markup Language と共に指定されています。
HTML の属性の多くは、すべての要素に対して使えますが、特定の要素にのみ利用可能な属性もあります。属性は、keyword="value" というかたちで表されます。値は、シングルクオートもしくはダブルクオートで囲まれます。クオートは、HTML5では必須ではありませんが、複数の単語で属性値を指定するときには、それが複数の属性値でなく一つの属性であることを明示するためにクオートを使用します。
属性と、それらが取りうる値は HTML 仕様で定義されています。つまり、HTML 文書を valid に保ちながら、独自に新しい属性を追加する事はできません。独自の属性を追加してしまうとユーザーエージェントを混乱させ、Web ページが適切に処理できない可能性もあります。例外としては、 id 属性と class 属性です。これらの属性は、文書に独自の意味やセマンティクスを与えるためのものなので、値を自由に決めることができます。
ある要素内に別の要素があるとき、内側の要素は外の要素の「子」と表現されます。さっきの例では、abbr は h1 要素の子要素で、またその h1 も header の子要素になります。逆に、header は h1 の「親」と表現されます。この「親子」という概念は CSS の基礎を構成し、また JavaScript で頻繁に使われるので、とても重要です。
ブロックレベル要素とインライン要素
HTML の要素は「ブロックレベル要素」と「インライン要素」というふたつの大きなカテゴリーに分けられます。これらは、要素の型や、要素が指し示すものの構造を表します。
ブロックレベル要素は上位レベルにの要素、一般的には文書の構造を表します。ブロックレベル要素は「それまでの行を終了し、新しい行をはじめる要素」と考えるとわかりやすいかもしれません。ブロック要素のうち広く使われるものに、段落、リスト項目、見出し、表があります。
インライン要素はブロックレベル要素の内側に含まれ、文書内容のうち一部分を囲むものです。ですから、段落全体や、内容をまとめるものではありません。インライン要素は新しい行を生成せず、テキストの段落内に表示されます。インライン要素のうち広く使われるものに、ハイパーリンク、言葉の強調表示や短い引用分があります。
文字参照
HTML について、最後にもうひとつ説明することがあります。特殊文字の書き方です。
HTML では、<、 >、 & は特別な文字になります。これらの文字は、タグなど HTML 文書を構成するパーツの開始・終了を表し、大なり、小なり、アンパサンドという記号を表しません。
Web ページを初めて作る人が犯しやすいミスのひとつに、アンパサンドをそのまま書くことがあります。そして、予期せぬ出来事に遭遇するのです。たとえば、“Imperial units measure weight in stones£s” という文を書くと、いくつかのブラウザーで “…stones£s” と表示されてしまいます。
これは、“£” という文字列が HTML の文字参照だからです。文字参照とは、キーボードや特定の文字コードにおいて入力できない/入力しづらい文字を HTML 文書内で表現する仕組みです。
そして、参照はアンパサンド (&) により開始され、セミコロン (;) によって終了されます。しかしながら、多くのユーザーエージェントが HTML の間違えを許容する特殊な処理を行い、セミコロンのない “£” のようなものも文字参照として扱います。参照は数値によるもの (数値参照) と短縮表記された言葉によるもの (実体参照) が存在します。
アンパサンドを文字として表示させたい場合は、"&" と記述する必要があります。これは文字実体参照ですが、"&" という数値参照も利用できます。evolt.org には文字参照が表でまとめられています。
Attributions
This content was originally published on DevOpera, Opera's Developer Network. .