The Basics of HTML
Summary
In this article, you will learn the basics of HTML and gain some insight into the structure and content of an HTML document.
Introduction
This article summarises the purpose and structure of HTML in a very high-level fashion, including how elements work, and what character references are. The articles that follow will go into more detail on specific parts of the HTML language.
What is HTML?
Most desktop applications that read and write files use specific file formats. For example, Microsoft Word uses “.doc” files and Microsoft Excel uses ".xls". These files contain the instructions on how to build the documents when they are opened, the contents of the document, and metadata about the document such as the author, the last modified date, and possibly even a list of changes.
HTML (HyperText Markup Language) is a language used to describe the contents of web documents. It uses a syntax containing markers (called elements) that are wrapped around content in the document to indicate how user agents (e.g., web browsers) should interpret that portion of the document.
A user agent is any software that is used to access web pages on behalf of users. There is an important distinction to be made here — all types of desktop browsers (such as Internet Explorer, Opera, Firefox, Safari, and Chrome) as well as alternative browsers for other devices (such as the Wii Internet channel, and mobile phone browsers like Opera Mini and WebKit on the iPhone) are user agents, but not all user agents are browsers. For example, the automated programs that Google and Yahoo! use to index the web for their search engines are user agents, but no human being is controlling them directly.
What HTML looks like
HTML is a plain textual representation of content and its general meaning. For example:
<p id="example">This is a paragraph.</p>
The <p> part is a marker, commonly called a tag, that means "what follows should be considered as a paragraph". Because it is at the start of the content it affects, it is an "opening tag". Likewise, the </p> tag indicates the end of the paragraph, and is thus a "closing tag". The opening tag, closing tag, and everything in between is called an element. Note: Many people use the terms “element” and “tag” interchangeably, which is incorrect. (The id="example" is an attribute-value pair; we’ll come back to these later.)
In most browsers there is a “Source” or “View Source” option, commonly under the “View” menu. Try this now: go to a web site, choose this option, and spend some time looking at the HTML that makes up the page.
The structure of an HTML document
A typical HTML document might look like this:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Example page</title>
</head>
<body>
<h1>Hello world</h1>
</body>
</html>
That document might look like this when rendered in a web browser:
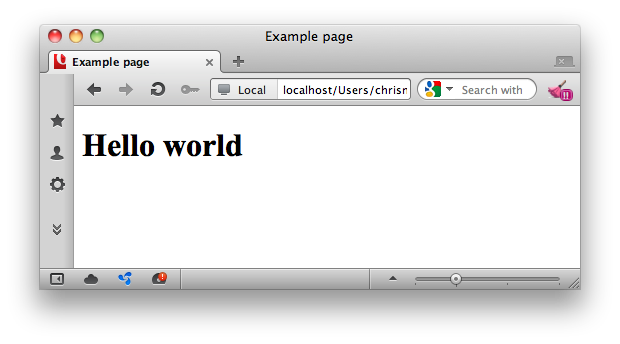
The document starts with a document type element, or doctype, in this case the HTML5 doctype. This mainly serves to get the browser to render the HTML in what is called "standards mode", so it will work correctly. It also lets validation software know what version of HTML to validate your code against.
Next, you can see the opening tag of the <html> element. This is a wrapper around the entire document. The closing </html> tag is the last thing in any HTML document. The html element should always have a lang attribute. This specifies the primary language for the page. For example, en means "English", fr means "French". There are tools available to help you find the right language tag, such as Richard Ishida’s Language Subtag Lookup tool.
Inside the html element, there is the head element. This is a wrapper that contains other information about the document such as internal or external styles and scripts. This is described in more detail in The HTML head element. Inside the head is the title element, which defines the “Example page” heading in the brower’s title bar. The head element should always contain a meta element with a charset attribute that identifies the character encoding of the page. (The one exception is when the page is encoded in UTF-16, but you should avoid that encoding anyway.) You should use UTF-8 whenever possible. See this W3C article for more about character encodings.
After the head element there is a body element, which is the wrapper that surrounds the actual content of the page — in this case, a level-one heading (h1) element, which contains the text "Hello world".
And that’s our document in full.
The syntax of HTML elements
A basic element in HTML consists of two markers around a block of content. Elements also often contain other elements, referred to as nested elements. The body of a document invariably contains many nested elements. Structural elements such as article, header, and div create the overall structure of the document, and will themselves contain headings, paragraphs, lists, and other elements. Paragraphs can contain elements that create links to other documents, quotes, emphasis, and so on. Nearly any element can contain nested elements, although there are exceptions: some elements do not contain either text or nested elements, for example img.
An element within another element is also referred to as a “child” element. So in the below example, abbr is a child of h1, which is itself a child of header. Conversely, the header element would be referred to as the “parent” of the h1 element, which is the parent of abbr. This parent/child concept is important, as it forms the basis of CSS (Cascading Stylesheet Specification) and is heavily used in JavaScript.
Elements can also have attributes, which can modify the appearance and/or behaviour of the element and introduce extra meaning. Let’s look at another example.
<header>
<h1>The Basics of
<abbr title="Hypertext Markup Language">HTML</abbr>
</h1>
</header>
This looks like so when rendered in a browser:

In this example, a header element contains an h1 heading element, which in turn contains some text. Part of that text is wrapped in an abbr element (used to specify the expansion of abbreviations), which has a title attribute, the value of which is Hypertext Markup Language.
Many attributes in HTML are common to all elements, though some are specific to certain elements. They are always of the form keyword="value". The value is often surrounded by single or double quotes. While this is not required in HTML5 (except when the attribute value has multiple words separated by white space), you should always quote values, as it is good practice and can make the code easier to read. In addition, some HTML dialects do require quoting of attributes, for example XHTML 1.0, and it doesn’t hurt to do so in dialects that don’t require it.
Attributes and their possible values are mostly defined by the W3C HTML specifications. You cannot make up your own attributes without invalidating the HTML, and this can confuse user agents and cause problems interpreting the web page correctly.
Block and inline elements
There are two general categories of elements in HTML, which correspond to the types of content and structure they represent: block elements and inline elements.
Block elements are at a higher level, normally helping to define the structure of the document. It may help to think of block elements as those that start on a new line, breaking away from the previous content. Some common block level elements include paragraphs, lists, headings, and tables.
Inline elements are are contained within block elements and typically surround only small parts of the document’s content. Inline elements do not cause a new line to appear in the document; rather, they appear inside a line of text. Some common inline elements include hypertext links, bold or italic text, spans, and short quotations.
Note: HTML5 redefines the element categories in HTML: see Element content categories. While these definitions are more accurate and less ambiguous, they are more difficult to understand than “block” and "inline". We will therefore stick with these terms in this course.
Character references
One last item to mention in an HTML document is how to include special characters. In HTML the characters <, > and & are special. They start and end parts of the HTML document, rather than representing the printable less-than, greater-than, and ampersand characters. For this reason they must always be coded in a special way in document content.
One of the easiest mistakes to make in a web page is to use < and > signs in text and have the browser render your content in an unexpected way. For example, if you write "The paragraph tag (<p>) is very common.", intending for it to look just like that, the browser will render it as
The paragraph tag (
) is very common.
This is clearly not what you wanted or expected.
The solution to this problem is to encode, or "escape", the two signs by representing them with character references. The character reference for less-than is "<", and the character reference for greater-than is ">". Thus, to get that line to look the way you want, you would write "The paragraph tag (<p>) is very common", which the browser would render as "The paragraph tag (<p>) is very common", as you intended. In these encodings, the ampersand (&) starts the reference and the semicolon (;) ends it.
Character references can also be numeric. For example, you can escape an ampersand character with either its shorthand word & or its numeric reference &.
Web Platform Docs includes a Table of Common HTML Entities for reference.
Other than these characters, you should try to avoid using character references unless you are dealing with an invisible or ambiguous character. If you use the UTF-8 character encoding you can represent any character (other than those mentioned above) without escaping them.
For more information about working with character escapes, see Using character escapes in markup and CSS.