HTML validation
Summary
This article introduces the concept of validation, and shows how to use the online W3C validator to validate your HTML.
Introduction
So you’ve written a few HTML pages, and they seem to display okay, but there are a few things not quite right with them. What is the best way to start finding out what is wrong, and to ensure that these pages (and any future pages you write) will be displayed properly across browsers, with no errors?
Validation is the answer! There are many tools available, from the W3C and other places, that allow you to validate the code on your sites. The most common validators you’ll use are:
- Validator.nu: A new-school validator that validates HTML5, ARIA, SVG 1.1 and MathML 2.0, it checks the entire document pointing out places where your markup doesn’t follow that doctype correctly (i.e., where there are errors). This is the one we recommend if you are using the HTML5 doctype, also highly recommended.
- The W3C MarkUp Validator: This looks at the (X)HTML doctype for the document you want to check, and then validates your markup accordingly. This is the one we recommend if you are using an HTML4 or XHTML1.x doctype. It does validate HTML5, but validator.nu is arguably more up to date.
- The W3C Link Checker: This checks a document, and tests all the links to make sure they are not broken (e.g., that the
<href>values point to resources that actually exist). - The W3C CSS Validator: This checks a CSS (or HTML/CSS) document and verifies that the CSS follows the specs properly.
In this article, we will cover how to use the second of these, demonstrating how to validate markup and interpret the typical kinds of results the validator gives you.
Errors
In computer programming — which includes markup languages — there are generally two types of errors with code:
- syntax errors — these errors usually involve a mistake that causes the computer to be unable to execute or compile the program properly (e.g., a missing brace or parenthesis).
- logic errors — these errors arise when the code is syntactically correct but doesn’t do exactly what it was meant to do.
With most programming languages, the first kind of error is impossible to overlook. The code will refuse to compile or run until the error is fixed, and the compiler will usually alert the programmer to the error and the line number on which it can be found. This makes finding and fixing syntax errors much easier than logic errors, which result in those general head-scratching moments of, “Why isn’t it doing what I want?” Validators, as you might expect, can only find syntax errors.
Although HTML is a declarative markup language rather than a procedural programming language, syntax errors may still occur. However, syntax errors in a web page do not commonly cause the web browser to refuse to display the page. This inherent forgiveness in web browsers is one of the biggest reasons for the rapid adoption and spread of the web. Even if you forget to close a tag, your page will usually still display.
The first web browser, WorldWideWeb (written by Tim Berners-Lee), was also an editor, allowing authors to create web pages without learning HTML. Although this editor created invalid HTML, it established an important precedent that exists in all web browsers to this day — that allowing users to access content is more important than complaining about errors to people who won’t understand them — or be in a position to fix them.
What is validation?
Although web browsers will accept invalid code in web pages and do their best to render the code by making a best guess of the author’s intention, it is still possible to check whether the HTML has been written correctly, and indeed it is a good idea to do so, as you’ll see below. We call this “validating” the HTML.
A validation program compares the HTML code in the web page with the rules of the accompanying doctype and tells you if and where those rules have been broken.
Why validate?
There is a common feeling among some web developers that if a web page looks fine in browsers, it doesn’t matter if it doesn’t validate (often stated as, “In function there is beauty”). They describe validation as an ideal goal, but not something that is a black-and-white issue.
There is some wisdom in this attitude. The HTML4 specification is not perfect, and some things that were arguably correct — such as starting an ordered list with a number other than 1 — were invalid HTML. HTML5 fixes quite a lot of spec issues, including this one, but you may still run into situations where validation may need to be broken in order to render the page as you want. As the saying goes, Learn the rules so you know how to break them properly.
There are two very powerful reasons to validate your HTML as you author it:
- You are not always perfect, and neither is your code. We all make mistakes, and your web pages will be higher quality (that is, work more consistently) if you weed out the mistakes.
- It is a fact of life that browsers change. In the future, it is likely that browsers will be less, not more, forgiving when parsing invalid code.
Validation is your early-warning system about bugs in your markup that can manifest in “interesting” and hard-to-fix ways. When a browser encounters invalid HTML, it has to take an educated guess as to what you meant to do — and different browsers can come up with different answers.
Different browsers interpret invalid HTML differently
Valid HTML is the only contract you have with the browser manufacturers. The HTML specification says how you should write documents, and how they should interpret them. In recent times, standards compliance of browsers has reached the point where, as long as you write valid code, all the major browsers should interpret your code the same way. This is almost always the case for HTML at least, with other standards having a few more differences in support here and there.
But what happens when you do pass a browser invalid code? The answer is that the browser’s error handling comes into play to work out what to do with the code. It basically says, “This code doesn’t validate, so how do I present this page to the end user?”
It sounds great, doesn’t it? If you leave a few errors in your page, the browser will fill in the gaps for you! Not so, as each browser does things differently. Consider the following code:
<p><strong>This text should be bold</p>
<p>Should this text be bold? How does the HTML look when rendered?</p>
<p><a href="#"></strong>This text should be a link</p>
<p>Should this text be a link? How does the HTML look when rendered?</p>
The errors are that (1) the strong element is incorrectly nested across multiple block elements, and (2) the anchor element is not closed. When you try to display this code in different browsers, they interpret it in very different ways:
- Opera makes the subsequent elements children of the bold element.
- Firefox adds extra bold elements between the paragraphs, which were not present in the markup.
- Internet Explorer puts the text “This text should be a link” outside the anchor tag that creates the link.
This original version of this example can be found in Hallvord Steen’s article Same DOM errors, different browser interpretations — read this for a deeper treatment of HTML errors, as well as some information about debugging tools.
None of the different browsers’ behaviors is incorrect; they’re all trying to fill in the gaps of your incorrect code, they just do it differently. The bottom line is, avoid invalid markup in your pages if at all possible!
Note that HTML5 fixes this to some degree; for the first time in the history of HTML, it defines how browsers should handle badly-formed markup. At the time of this writing, however, support for this HTML5 error handling is not widespread across browsers, so you can’t yet rely on it.
How to validate your pages
Now that we’ve explored the theory behind validating your HTML, let’s talk about the easy part — the actual validation. Okay, that’s not completely accurate. Putting a URL into a validator to see whether the page is valid is easy; working out what is wrong and fixing the errors is sometimes not so easy, as the error messages can sometimes be a bit cryptic. Let’s look at some examples.
The example we’ll be looking at in this section is below; feel free to copy and paste it into a new page in your favorite editor.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="en">
<head>
<title>Validating your HTML</title>
</head>
<body>
<h2>The tale of Herbet Gruel</h2>
<p>Welcome to my story. I am a slight whisp of a man, slender and fragile, features wrinkled and worn, eyes sunken into their sockets like rabbits cowering in their burrows. The <em>years have not been kind to me</em>, but yet I hold no regrets, as I have overcome all that sought to ail me, and have been allowed to bide my time, making mischief as I travel to and fro, 'cross the unyielding landscape of the <a href="http://outer-rim-rocks.co.uk" colspan="3">outer rim</a>.</p>
<h3>Buster</h3>
<p>Buster is my guardian angel. Before that, he was my dog. Before that, who knows? I lost my dog many moons ago while out hunting geese in the undergrowth. A shot rang out from my rifle, and I called for Buster to collect the goose I had felled. He ran off towards where the bird had landed, but never returned. I never found his body, but I comfort myself with the thought that he did not die; rather he transcended to a higher place, and now watches over me, to ensure my well-being.
<h3>My possessions</h3>
<p>A travelling man needs very little to accompany him on the road:</p>
<ul>
<li>My hat full of memories</li>
<li>My trusty walking cane</li>
<li>A purse that did contain gold at one time</li>
<li>A diary, from the year 1874<li>
<li>An empty glasses case</li>
<li>A newspaper, for when I need to look busy</li>
</ul>
</body>
This simple page consists of three headings, three paragraphs, one hyperlink, and one unordered list. It uses the XHTML 1.0 strict doctype as its rule set to validate against. (We used XHTML 1.0 strict because it is more likely to throw errors than the HTML5 doctype.) There are a few errors in the document, which we’ll discover below using the W3C HTML validator.
The W3C HTML validator
Open the W3C online validator in a new tab or window, so that you can switch between the validator and this article as you go through the example. (You can also validate pages in the W3C validator directly from the Opera browser by right/Ctrl-clicking and selecting the “Validate” option.)
You’ll notice that the validator has three tabs available across the top of the interface:
- Validate by URI: Allows you to enter the address of a page already on the internet for validation.
- Validate by File Upload: Allows you to upload a local HTML file for validation.
- Validate by Direct Input: Allows you to paste HTML directly into the window for validation.
Whichever method you use should give you the same result; it’s easiest to test the example page from here by copying the full example code from above and pasting it into the third tab. Doing so should give you the result shown in Figure 1:
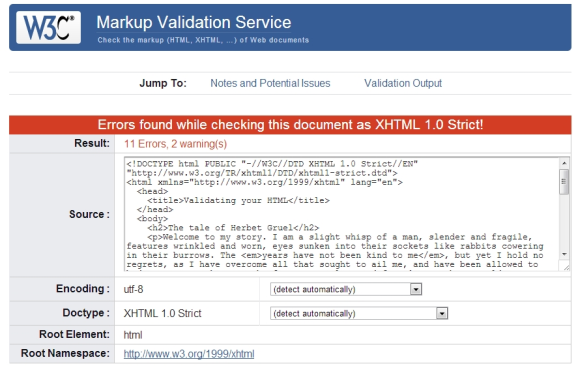
Figure 1: The results of validating the sample document — 11 errors!
This may sound worrying, especially when we tell you that there are not 11 errors in the document! Don’t despair — the validator is reporting more errors than there actually are. This is because often an error at the top of the page will cascade, making the validator report more errors further down, as it looks like more elements are not closed or incorrectly nested. You just have to think about what the error messages mean, look for obvious errors in the markup, and work from the top down. Table 1 below shows all of the errors we fixed to make the page validate, along with our logic for working out what was wrong, and the fixes we applied to solve the problem.
| Error message | Resolution logic | Fix made |
|---|---|---|
| Line 8, Column 461: there is no attribute “colspan” | We know that there is a colspan attribute, and it is valid HTML, so why is it saying it doesn’t exist? Wait, maybe it means it is being used on an element that you shouldn’t use it on? Sure enough, it is being used on an <a> element — wrong! | Removed the colspan attribute from the <a> element. |
Line 13, Column 7: document type does not allow element “h3” here; missing one of "object", "applet", "map", "iframe", "button", "ins", “del” start-tag. <h3>My possessions</h3> | Again, at first glance this seems strange — the <h3> element is properly closed, and allowed in this context. You should note that often, this error message means that there is an unclosed element nearby. | Added a closing <p> tag to the line above the heading in question. |
Line 19, Column 40: document type does not allow element “li” here; missing one of "ul", "ol", "menu", “dir” start-tag. <li>A diary, from the year 1874<li> | This one is pretty easy — you can see from the line it is pointing to that the end <li> tag is missing a closing slash (/). | Added a closing slash to the line in question. |
Line 23, Column 9: end tag for “html” omitted, but OMITTAG NO was specified. </body> | Again, it doesn’t take much to work out that this means the end <html> tag is missing. The error message explanation even starts with You may have neglected to close an element. | Added the missing end </html> element. |
With these four errors fixed, the remaining seven disappear and the validator now gives a satisfying success message, as shown in Figure 2:
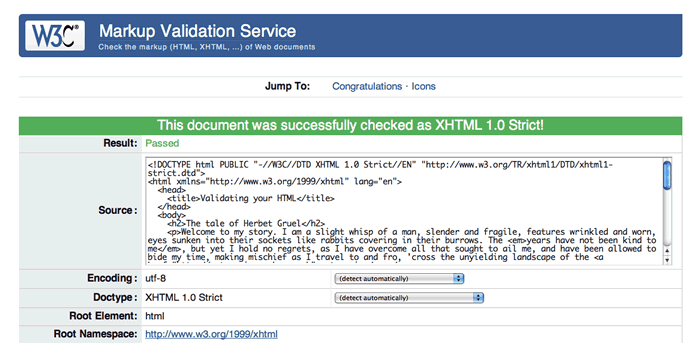
Figure 2: A success message to say that all my errors have been fixed.
Below is the corrected version of the code; feel free to copy and paste it into a new page in your favorite editor.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="en">
<head>
<title>Validating your HTML</title>
</head>
<body>
<h2>The tale of Herbet Gruel</h2>
<p>Welcome to my story. I am a slight whisp of a man, slender and fragile, features wrinkled and worn, eyes sunken into their sockets like rabbits cowering in their burrows. The <em>years have not been kind to me</em>, but yet I hold no regrets, as I have overcome all that sought to ail me, and have been allowed to bide my time, making mischief as I travel to and fro, 'cross the unyielding landscape of the <a href="http://outer-rim-rocks.co.uk">outer rim</a>.</p>
<h3>Buster</h3>
<p>Buster is my guardian angel. Before that, he was my dog. Before that, who knows? I lost my dog many moons ago while out hunting geese in the undergrowth. A shot rang out from my rifle, and I called for Buster to collect the goose I had felled. He ran off towards where the bird had landed, but never returned. I never found his body, but I comfort myself with the thought that he did not die; rather he transcended to a higher place, and now watches over me, to ensure my well-being.</p>
<h3>My possessions</h3>
<p>A travelling man needs very little to accompany him on the road:</p>
<ul>
<li>My hat full of memories</li>
<li>My trusty walking cane</li>
<li>A purse that did contain gold at one time</li>
<li>A diary, from the year 1874</li>
<li>An empty glasses case</li>
<li>A newspaper, for when I need to look busy</li>
</ul>
</body>
</html>
Conclusion
That’s about all there is to it, really. You just need to keep your wits about you, code carefully, and remember what doctype your page is being validated against.
See also
External resources
- Opera Dragonfly (built into Opera)
- General validation bookmarklet
- The Firefox web developer toolbar extension
- The IE developer toolbar
- Safari tidy
- HTML tidy
Exercise questions
- What happens when a browser parses invalid HTML?
- What is the problem with this?
- Will using a frameset in a document validated against the HTML 4 Strict doctype generate an error?