How does the Internet work?
Summary
Every so often, you get offered a behind-the-scenes look at the cogs and fan belts behind the action. Today is your lucky day. In this article we will usher you behind the scenes of one of the hottest technologies that you might already be familiar with: the World Wide Web. Cue theme music.
This article covers the underlying technologies that power the World Wide Web:
- Hypertext Markup Language (HTML)
- Hypertext Transfer Protocol (HTTP)
- Domain Name System (DNS)
- Web servers and web browsers
- Static and dynamic content
While most of what is covered here will not help you to build a better website, it will give you the proper language to use when speaking with clients and with others about the Web. It is like a wise nun-turned-nanny once said in The Sound of Music: “When we read we begin with ABC. When we sing we begin with Do Re Mi.” In this article I will briefly look at how computers actually communicate, then go on to look at the different languages that work together to create the web pages that make up the Web.
How do computers communicate via the Internet?
Thankfully, we have kept things simple for computers. When it comes to the World Wide Web, most pages are written using the same language, HTML, which is passed around using a common protocol — HTTP. HTTP is the common internet language (dialect, or specification), allowing a Windows machine, for example, to sing in harmony with a machine running the latest and greatest version of Linux (Do Re Mi!). Through the use of a web browser, a special piece of software that interprets HTTP and renders HTML into a human-readable form, web pages authored in HTML on any type of computer can be read anywhere, including telephones, PDAs and even popular games consoles.
Even though they are speaking the same language, the various devices accessing the web need to have some rules in place to be able to talk to one another — it is like learning to raise your hand to ask a question in class. HTTP lays out these ground rules for the Internet. Because of HTTP, a client machine (like your computer) knows that it has to be the one to initiate a request for a web page; it sends this request to a server. A server is a computer where websites reside — when you type a web address into your browser, a server receives your request, finds the web page you want, and sends it back to your computer to be displayed in your web browser.
Dissecting a request/response cycle
Now that we have looked at all the parts that allow computers to communicate across the Internet, let us look at the HTTP request/response cycle in more detail. There are some numbered steps below for you to work along with, so I can demonstrate some of the concepts to you more effectively.
- Every request/response starts by typing a URL (commonly known as a web address) into the address bar of your web browser, something like http://www.apple.com. Open a browser now, and type this URL and press Enter/Return (or follow the above link) to go to the Apple homepage. Now, one thing you may not know is that web browsers actually do not use URLs to request websites from servers; they use Internet Protocol or IP addresses (which function like phone numbers or postal addresses, but identify servers, rather than phones or addresses). For example, the IP address of http://www.apple.com is 17.149.160.49
- Try opening a new browser tab or window, typing http://17.149.160.49/ into the address bar and hitting enter — you will get the same web page that you got to in step 1. http://www.apple.com is basically acting as an alias for http://17.149.160.49/, but why, and how? This is because people are better at remembering words than long strings of numbers. The system that makes this work is called DNS, which is a comprehensive automatic directory of all of the machines connected to the Internet. When you punch http://www.apple.com into your address bar and hit enter, that address is sent off to a name server that tries to associate it to its IP address. There are a literally millions of machines connected to the Internet, and not every DNS server has a listing for every machine online, so there is a system in place where your request will be referred on to another name server to fulfill your request, if the first one does not have the right information. So the DNS system looks up the Apple website, finds that it is located at 17.149.160.49, and sends this IP address back to your web browser. Your machine then sends a request to the machine at the IP address specified and waits to get a response back. If all goes well, the server sends a short message back to the client with a message saying that everything is okay (see Figure 1,) followed by the web page itself. This type of message is contained in an HTTP header.
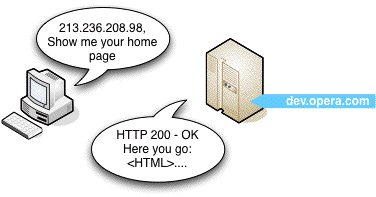
Figure 1: In this case, everything is fine, and the server returns the correct web page. If something goes wrong, for example you typed the URL incorrectly, you will get an HTTP error returned to your web browser instead — the infamous 404 “page not found” error is the most common example you will come across.
- Try typing in http://www.joniscool.co.uk/jonlane/. The page does not exist, so you will get a 404 error returned. Try it with a few different fake page addresses and you will see a variety of different pages returned. This is because some web developers have just left the web server to return their default error pages, and others have coded custom error pages to appear when a non-existent page is returned. This is an advanced technique that will not be covered in this course, but Stuart Colville provides a good article on it at Adding meaning to your HTTP error pages!. Lastly, a note about URLs — usually the first URL you go to on a site does not have an actual file name at the end of it (eg http://www.mysite.com/), and then subsequent pages sometimes do and sometimes do not. You are always accessing actual files, but sometimes the web developer has set up the web server to not display the file names in the URL — this often makes for neater, easier to remember URLs, which leads to a better experience for the user of your website. We will not cover how to do this in this course, as again, it is quite advanced; we cover uploading files to a server and file/folder directory structures in Getting your content online, by Craig Grannell.
Types of Content
Now you’ll look at the different types of content you’ll expect to see on the Internet. They are grouped these into 4 types — plain text, web standards, server-side languages, and formats requiring other applications or plugins.
Plain text
In the really early days of the Internet, before any web standards or plugins came along, the Internet was mainly just images and plain text — files with an extension of .txt or similar. When a plain text file is encountered on the Internet, the browser will just display it as is, without any processing involved. You often still get plain text files on university sites.
Web Standards
The basic building blocks of the World Wide Web are the three most commonly-used web standards — HTML, CSS and JavaScript.
Hypertext Markup Language is actually a pretty good name as far as communicating it is purpose. HTML is what is used to divide up a document, specify its contents and structure, and define the meaning of each part (headings, paragraphs, bulleted lists, etc.) It uses elements to identify the different components of a page.
Cascading Style Sheets give you complete control over how an element is styled and positioned. It is easy, using style declarations, to change all paragraphs to be double-spaced (line-height: 2em;), or to make all second-level headings green (color: green;). There are a ton of advantages to separating the structure from the style, and we will look at this in more detail [in the next article]. To demonstrate the power of HTML and CSS used together, Figure 2 shows some plain HTML on the left, with no formatting added to it at all, while on the right you can see exactly the same HTML with some CSS styles applied to it.

Figure 2: Plain HTML on the left, HTML with CSS applied to it on the right.
Finally, JavaScript provides dynamic functions to your website or web application. You can write programs in JavaScript that will run in the web browser, requiring no special software to be installed. JavaScript allows you to add powerful interactivity and dynamic features to your website, but it has its limitations, which brings us to server-side programming languages, and dynamic web pages.
Server-side languages
Sometimes, when browsing the Internet, you will come across web pages that do not have an .html extension—they might have a .php, .asp, .aspx, .jsp, or some other strange extension. These are all examples of server-side web technologies, which can be used to create web pages with sections that change depending on variable values given to the page on the server, before the page is sent to the web browser to be displayed. For example, a movie listings page could pull movie information from a database, and display different movie information for different days, weeks or months. We will cover these types of web pages further in the Static versus Dynamic pages section below.
Formats requiring other applications or plugins
Because web browsers are only equipped to interpret and display certain technologies like web standards, if you have requested a URL that points to a file format the browser is not able to interpret, or a web page containing a technology requiring plugins, it will either be downloaded to your computer or opened using a plugin if the browser has it installed. For example:
- If you encounter a Word document, Excel file, PDF, compressed file (ZIP, or RAR), complex image file such as a Photoshop PSD, or another file that the browser does not understand, the browser will usually ask you if you want to download or open the file. Both of these usually have similar results, except that the latter will cause the file to be downloaded and then opened by an application that does understand it, if one is installed.
- If you encounter a page containing a Flash movie, Java Applet, or music of video file that it does not understand, the browser will play it using an installed plugin, if one has been installed. If not, you will usually be given a link to install the required plugin, or the file will download and look for a desktop application to run it.
Of course, there are some gray areas—for example some browsers will come with some plugins pre-installed, so you may not be aware that content is being displayed via a plugin and not natively within the browser.
Static vs. Dynamic Websites
So what are static and dynamic websites, and what is the difference between the two? Similar to a box of chocolates, it is all in the filling:
A static website is a website where the content (eg the HTML and graphic content) is always static—it is served up to any visitor the same, unless the person who created the website decides to manually change the copy of it on the server—this is exactly what we have been looking at throughout most of this article.
On a dynamic website, the content on the server is similar, but it also contains dynamic code instead of just HTML. Dynamic code may display different data depending on information such as the time of day, the user who is logged in, the date, and the search term it has been given to look for. Let us look at an example — navigate to www.amazon.com in your web browser, and search for 5 different products. Amazon has not sent you 5 different pages; it has sent you the same page 5 times, but with different dynamic information filled in each time. This different information is kept in a database, which pulls up the relevant information when requested, and gives it to the web server to insert into the dynamic page.
Another thing to note is that special software must be installed on the server to create a dynamic website. Whereas normal static HTML files are saved with a file extension of .html and can just be run by the browser with no extra help, these files contain special dynamic code in addition to HTML, and are saved with special file extensions to tell the web server that they need extra processing before they are sent to the client (such as having the data inserted from the database). PHP files for example usually have a .php file extension.
While the server for a dynamic website may be processing special dynamic code, it is still sending HTML to the client. The client does not need plugins for these special file extensions because the client is still getting what looks like an HTML file.
There are many dynamic languages and frameworks to choose from — I have already mentioned PHP, and other examples include Python, Ruby on Rails, ASP.NET and Coldfusion. In the end, all of these technologies have pretty much the same capabilities, like talking to databases, validating information entered into forms, etc., but they do things slightly differently, and have some advantages and disadvantages. It all boils down to what suits you best.
We will not be covering dynamic languages any further in this course, but I have provided a list of resources here in case you want to go and read up on them:
- Rails: Fernandez, Obie. (2007), The Rails Way. Addison-Wesley Professional Ruby Series.
- Rails screencasts
- PHP: Powers, David (2006), PHP Solutions: Dynamic web development made easy, friends of ED.
- PHP Online documentation
- PHP The Right Way
- The PHP League, a set of tested PHP packages using modern coding standards
- ASP.NET: Lorenz, Patrick. (2003). ASP.NET 2.0 Revealed. Apress.
- ASP.NET: [online ASP.NET documentation and tutorials.]
- Backbone fundamentals
Summary
That is it for the behind-the-scenes tour of how the Internet works. This article really just scratches the surface of a lot of the topics covered, but it is useful as it puts them all in perspective, showing how they all relate and work together. There is still a lot left to learn about the actual language syntax that makes up HTML, CSS and JavaScript, and this is where we will go to next — the next article focuses on the HTML, CSS and JavaScript “web standards” model of web development, and takes a look at web page code.
Notes
Exercise questions
- Provide a brief definition for HTML and HTTP and explain the difference between the two.
- Explain the function of a web browser.
- Have a look around the Internet for about 5–10 minutes and try to find some different types of content—plain text, images, HTML, dynamic pages such as PHP and .NET (.aspx) pages, PDFs, word documents, Flash movies etc. Access some of these and have a think about how your computer displays them to you.
- What is the difference between a static page and a dynamic page?
- Find a list of HTTP error codes, list 5 of them, and explain what each one means.